
AWS上でインフラの運用管理を任されている方にとって、「AWSリソースの監視」は大きな関心事ではないでしょうか。本記事では、AWS環境における監視の基本知識から、Amazon CloudWatchなどの標準ツールやサードパーティ製ツールの活用方法、代表的な監視ツールの比較、さらに運用フェーズでのベストプラクティスや自動化手法、そしてよくあるトラブルへの対策まで、幅広く解説していきます。
監視を適切に行うことで、システムの安定稼働やセキュリティ強化、コスト最適化につながります。本記事の内容を参考に、実務でAWS監視を活用できるようにしていきましょう。
この記事でわかること
① AWSで監視が必要な4つの理由
② AWSで提供される監視ツールの活用方法
③ 監視ツール4選の特徴とユースケース
④ 監視運用の効率化を支えるベストプラクティス
⑤ AWSの監視でよくあるトラブルとその対策
目次
AWS監視の基礎知識
AWSにおける監視とは、AWS上で動作するシステムやリソースの状態を継続的にモニタリングし、問題発生時にすばやく検知・通知して対処することを指します。オンプレミス環境とは異なり、AWSでは各種クラウドサービスの稼働状況も含めて監視する必要があり、可用性・性能・セキュリティ・コストなど多面的な観点からシステムを見守ることが重要です。ここではまず、監視が必要な主な理由について押さえておきましょう。
AWSで監視が必要な4つの理由
監視を適切に実施することは、AWS環境の安定運用に欠かせません。その理由として、大きく「可用性の確保」「パフォーマンスの最適化」「セキュリティの強化」「コスト最適化」の4つが挙げられます。以下では順に見ていきましょう。

可用性の確保 (応答時間、エラー率)
まず第一に、システムの可用性を確保するという目的のために監視は必須です。こちらはイメージしやすいかと思いますが例えば、サーバーダウンやアプリケーションのエラーなど障害が発生した際、監視を行っていることによって早期に検知でき、ダウンタイムを最小限に抑えられます。
例えばWebサイトの応答時間やエラー率を常時モニタリングし、閾値を超えれば即アラートを上げることで、管理者が迅速に対応できる体制を整えます。仮に監視アラートがなければ問題に気付けず、ユーザーへのサービス停止や大きな業務影響を招きかねません。
パフォーマンスの最適化 (CPU、メモリ、ディスクI/O)
システムのパフォーマンスを最適化することも監視の重要な目的です。CPU使用率・メモリ消費量・ディスクI/Oといったリソース利用状況を継続的に監視することで、ボトルネックや負荷の高まりをいち早く察知できます。
例えばCPU使用率が常に高止まりしていればスケールアウトやインスタンスタイプ変更を検討できますし、メモリ逼迫が見られればメモリ増強やプログラムのメモリリーク対策が必要かもしれません。適切なメトリクス監視によりパフォーマンス低下を未然に防ぎ、ユーザーへのサービス品質を維持できます。また、こうした性能データを蓄積分析することで将来の容量計画にも役立ちます。
セキュリティの強化 (不正アクセス、異常行動)
クラウド上のリソースを守るため、セキュリティ監視の強化も欠かせません。具体的には、不正アクセスの試行や異常なユーザー行動を検知するためにログやトラフィックの監視を行います。例えばサーバのアクセスログやAWS CloudTrailログを監視すれば、通常とは異なるIPアドレスからのアクセスや失敗したログインの連続発生などをいち早く発見できます。
AWSのようなクラウド環境では悪意のあるトラフィックやログの分析を行うために、Amazon GuardDutyやAWS Configといったサービスと連携したモニタリングも有効です。監視によってセキュリティインシデントの兆候を捉え、迅速な対応・被害拡大の防止につなげることが可能です。
コストの最適化 (リソース利用状況)
AWS利用において見逃せないのがコストの最適化です。必要以上のリソースを使いすぎていないか監視し、無駄な稼働を減らすことでクラウド利用料を抑制できます。例えばCPUやメモリの使用率が低いまま稼働し続けているインスタンスはないか、ストレージ容量に無駄がないか、一定期間使われていないリソースが放置されていないか、といった点を監視で可視化します。
こうした情報に基づき不要なリソースを停止・削除すれば、運用コスト削減につながります。さらに、CloudWatchの料金アラーム機能を使えば月々のAWS利用料金を監視し、急激なコスト増加があれば通知を受けることも可能です。
AWS監視ツールで最低限押さえておきたい活用方法
AWS環境の監視には、主にAWS公式のサービスであるAmazon CloudWatchを中心に、さまざまなツールや機能が用意されています。ここでは、AWSの監視ツールを使う上で最低限知っておきたい基本的な活用方法を解説します。
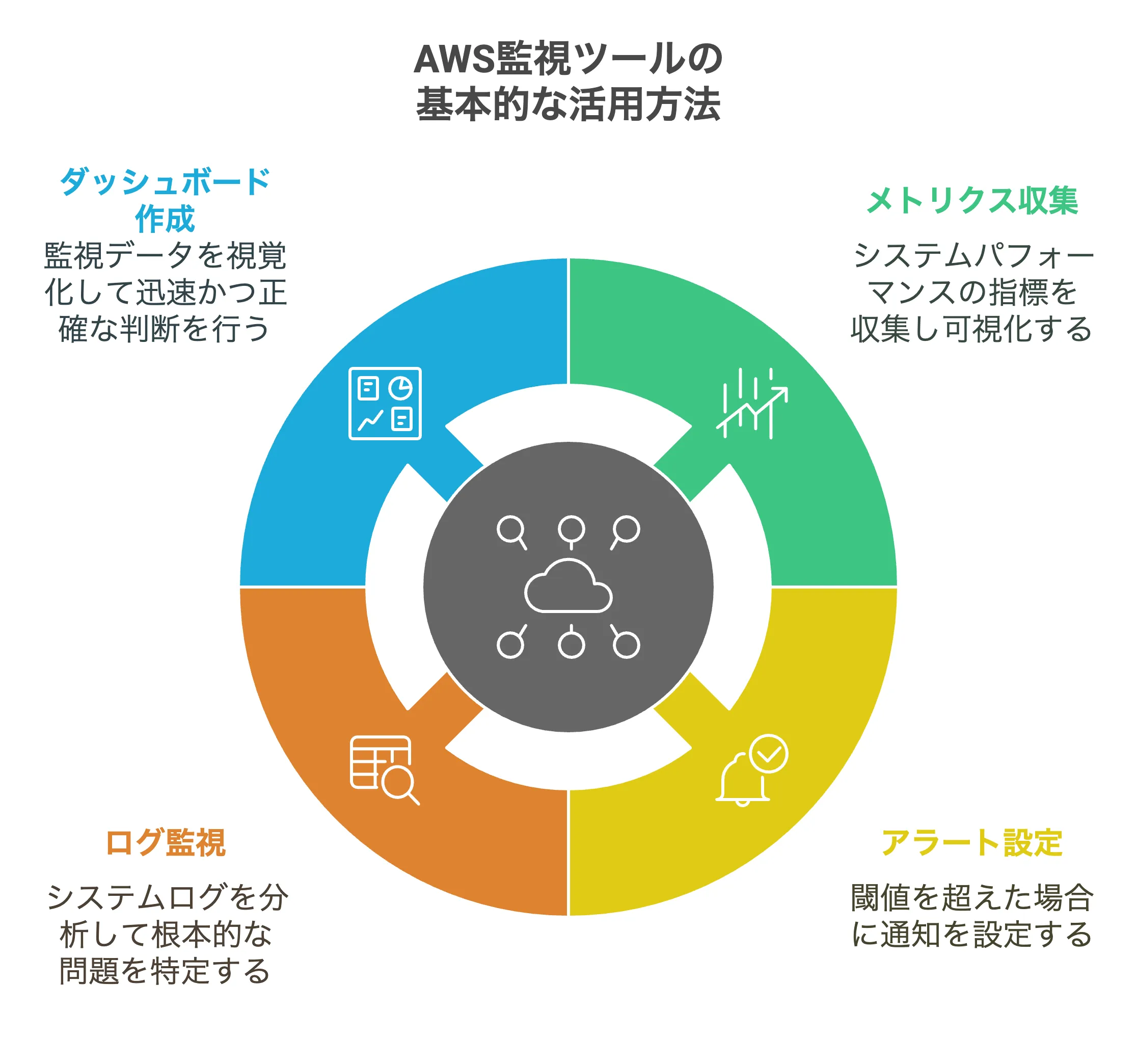
メトリクス収集とアラート設定の基本
AWS監視の基本は、システムの様々なメトリクス(指標)を収集・可視化し、閾値を設定してアラートを発することです。Amazon CloudWatchはAWSの主要サービスに対して標準メトリクスを自動収集しており、例えばEC2インスタンスのCPU使用率やネットワークIO、Amazon RDSのストレージ使用量などがデフォルトで記録されています。
CloudWatchではこれらメトリクスに対し閾値を設定してCloudWatchアラームを作成できます。アラームは指定したメトリクスが一定期間 閾値を超過した場合に発火し、管理者への通知やリソースの自動操作を行う仕組みです。
例えば「EC2のCPU使用率が5分間平均80%を超えたらアラート発報」のように設定すれば、高負荷時にメールやSMSで知らせてくれます。また、アラーム発生時のアクションとしてAWS Lambda関数を実行したり、オートスケーリングをトリガーして自動でサーバー台数を増やすことも可能です。
さらにアラート通知にはAmazon SNSという通知サービスと連携し、メール・チャットなど多様な方法で受け取れます。
ログ監視と分析(CloudWatch Logs Insightsの活用)
システムやアプリケーションのログ監視と分析もAWS運用では重要な役割を担います。AWSにはAmazon CloudWatch Logsというサービスがあり、各種ログを集中的に取り込み保管できます。例えば、EC2のシステムログやアプリケーションログ、Lambdaの実行ログ、VPCフローログ、CloudTrail(操作履歴)ログなど、AWS上の様々なログをCloudWatch Logsに送っておけば、一元的なログ監視基盤が構築できます。
さらにCloudWatch Logsには強力なログ分析機能「CloudWatch Logs Insights」が備わっています。このLogs Insightsを使うことで、収集された膨大なログデータをインタラクティブに検索・分析することが可能です。
イメージとしては、専用のクエリ言語を用いてログに含まれるエラーメッセージの発生頻度を集計したり、特定ユーザーIDに関するイベントのみ抽出したりといった柔軟な解析ができ、問題発生時の原因特定やトラブルシューティングに威力を発揮します。例えばアプリケーションエラーが起きた際、Logs Insightsで直近のログからエラーコードやスタックトレースを検索すれば、根本原因の絞り込みが素早く行えます。
また、CloudWatch Logsではログ内容に基づいてメトリクスフィルタを作成し、ログに特定の文字列(例: “ERROR”)が記録された回数をメトリクス化することもできます。このカスタムメトリクスにアラームを設定すれば「一定時間にエラーがN回以上発生した」ことを検知して通知する、といったログ監視アラームも実現できます。このようにログ監視とログ分析を組み合わせることで、潜在的な問題を早期発見しシステムの信頼性を高めることができます。
ダッシュボード作成で可視化するポイント
監視したいメトリクスやログを効率よく把握するには、ダッシュボードを作成して可視化する方法が有効です。Amazon CloudWatchにはCloudWatchダッシュボード※1という機能があり、任意のメトリクスグラフやアラーム状態、ログインサイトなどを1つの画面にまとめて表示できます。
例えばEC2インスタンス群のCPU利用率やネットワークトラフィック、RDSデータベースの接続数、主要なアプリケーションログの一部など、運用上重要な情報を複数ウィジェットとして配置すれば、システム全体の健康状態をひと目で確認可能です。
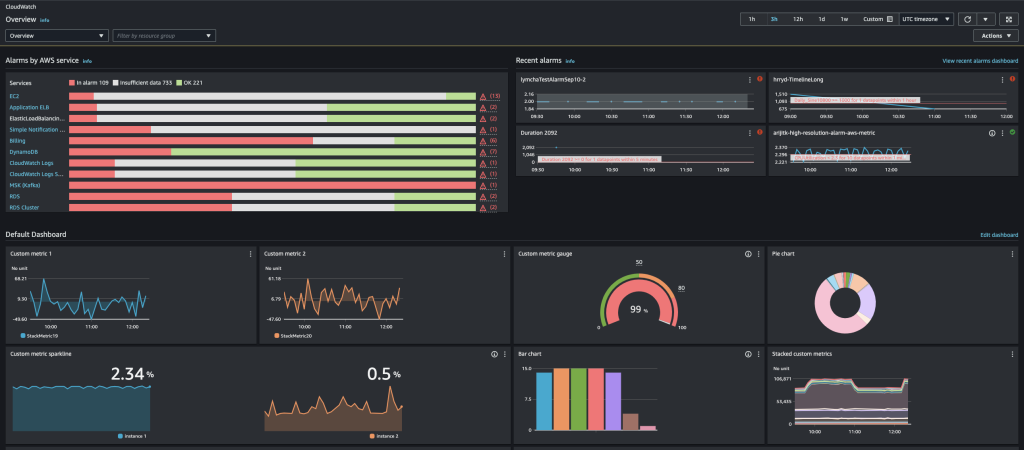
実際に上記画像のようにダッシュボードは用途に応じてカスタマイズ可能で、サービスごとに個別のダッシュボードを作成したり、担当チームや部署別に監視項目をレイアウトしたりできます。CloudWatchダッシュボードを上手く活用すれば、CPUやメモリなどリソース利用状況からアラームの発生状況、さらにはログの内容まで様々な情報を一つの画面で確認でき、運用監視の効率が向上します。
代表的な監視ツール4選と特徴比較
AWS環境の監視を実現するツールは数多く存在します。ここでは代表的な4つの監視ツールとして、先ほどから触れていたAWS純正ツール「Amazon CloudWatch」、そしてサードパーティ製の「Datadog」「Zabbix」「Mackerel」を取り上げ、それぞれの特徴を比較します。各ツールの強みや注意点を理解し、自社の要件に合ったものを選定する参考になれば幸いです。
AWS純正ツール
Amazon CloudWatch
Amazon CloudWatchはAWSが提供するマネージド型の監視サービスです。AWS上の多くのサービスのメトリクスをカバーしており、AWS環境に最適化されたリアルタイムモニタリングとアラート機能を備えています。
AWSの管理コンソール上で完結して設定でき、他のAWSリソースとの統合がスムーズで扱いやすい点も大きなメリットです。例えばEC2やRDSなどのメトリクスは追加設定なしで自動収集され、ワンクリックでグラフ表示やアラーム設定が可能です。
また前述のようにダッシュボード機能やログ監視機能も充実しており、AWS運用における統合的な監視プラットフォームと言えます。ただしAWS専用のサービスであるため、マルチクラウド環境やオンプレミスのみの環境にはそのままでは適用しづらいという注意点があります。総じてCloudWatchは「AWSで監視を行うならまずこれ」と言えるような基本ツールであり、特にAWSリソースの監視において高い利便性を発揮します。
サードパーティツール
Datadog

Datadog(データドッグ)はクラウド全般のモニタリングに定評のあるSaaS型監視ツールです。アプリケーションのパフォーマンス監視に強みがあり、インフラ監視・ログ管理・APM(アプリ監視)など複数の機能を統合することでシステム全体を一元的にモニタリングできます。
AWS環境とも連携が容易で、CloudWatchのメトリクスをDatadog側に取り込んでダッシュボード表示したり、DatadogエージェントをEC2に入れてOSレベルの詳細なメトリクス(例:メモリ使用率やディスクIO待ち時間)を取得したりすることも可能です。
またリアルタイム性と多機能な可視化UIにも優れており、直感的なダッシュボード編集や多彩なアラート条件設定ができる点が特徴です。例えば機械学習を用いた異常検知アラートでは、従来は難しかった動的な閾値による通知も実現できます※2。
無料プランでも最大5ホストまでモニタ可能ですが、本格的に使うにはコストとのバランス検討が必要です。総じてDatadogはマルチクラウドや複雑なアプリ環境をまとめて監視したい場合に有力な選択肢であり、高度な可視化・分析機能によってデータの観測性(オブザーバビリティ)を高めてくれるでしょう。
※2 エンタープライズプランで提供
Zabbix
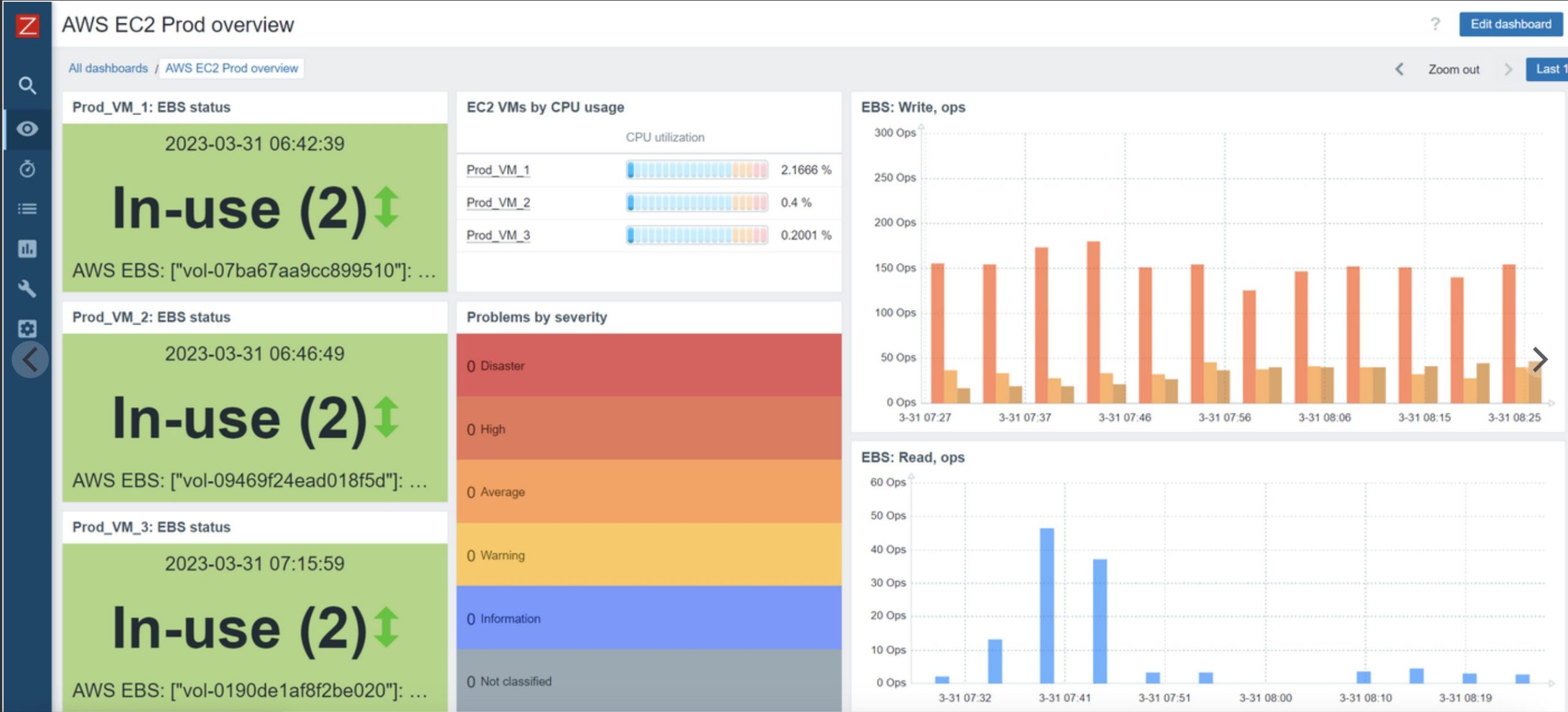
Zabbix(ザビックス)はオンプレミスからクラウドまで幅広く利用されているオープンソースの監視ツールです。自社サーバ上にインストールして利用するタイプで、高度なカスタマイズ性と豊富な監視テンプレートを備えている点が特徴です。エージェントを各サーバに導入することで細かなメトリクス取得が可能で、AWS環境に対してもCloudWatch API経由でメトリクスを取り込んだり、各種クラウドリソースを監視対象に含めたりできます。
Zabbixの強みはその柔軟性で、オンプレミスとAWSのハイブリッド環境や複雑なネットワーク構成にも対応でき、大規模環境でもスケーラブルに運用できます。一方で導入・運用の難易度はやや高めです。サーバソフトウェアとして自前でセットアップし、データベースやWebインターフェースを含めて構築する必要があるため、初期構築や設定に時間がかかります。
また多数の監視項目を扱う場合のチューニングやメンテナンスも発生します。しかしその分、自社ニーズに合わせ細部まで作り込んだ監視システムを構築できるのが魅力です。費用面ではオープンソースにつきソフトウェア利用自体は無料であり、大規模でもライセンス費用を気にせず展開できます。総合するとZabbixは「自分たちで細かく制御できる監視基盤が欲しい」ケースに適したツールであり、必要な機能を取捨選択しながら強力な監視システムを構築できるでしょう。
Mackerel
Mackerel(マカレル)は日本発のSaaS型監視サービスで、クラウドネイティブなアプリケーションのモニタリングに強みを持っています。Hatena社によって開発・提供されており、シンプルで見やすいUIと設定のしやすさから国内でも多くのユーザーに利用されています。
Mackerelエージェントをサーバにインストールすることで、CPUやメモリ、ディスク、プロセス数といった基本的なメトリクスは自動収集され、Web上のダッシュボードでリアルタイムに確認できます。監視対象ごとに「ロール」という概念でグルーピングでき、マイクロサービスごと・環境(本番/開発)ごとに柔軟な設定が可能な点もメリットです。
また、Webhook連携や外形監視(サイトの応答チェック)機能、Slack通知など運用に役立つ機能も豊富です。Mackerelは高い可用性と実績を備えており、大規模サービスの監視にも導入例があります。注意点としては、他のSaaS監視ツールとの連携がやや限定的な点や、利用規模によっては費用が嵩むケースがある点です。
特に収集データが多くなると上位プランへの加入が必要になり、Amazon CloudWatchに比べコスト高となる場合があります。それでも「簡単に素早く監視を始めたい」「国産ツールの手厚いサポートを受けたい」という場合には有力な選択肢となるでしょう。総じてMackerelは扱いやすさと必要十分な機能を兼ね備えたバランスの良い監視サービスであり、中小規模から大規模まで幅広いAWS環境で活用されています。
運用フェーズで押さえるベストプラクティス
AWS監視を導入した後の運用フェーズでは、監視体制を継続的に改善しつつ安定運用を図ることが求められます。ここでは、運用段階で意識すべきベストプラクティスとして、「監視設定のコード管理(IaC)」「小規模かつ可逆的な変更の徹底」「インシデント対応フローの整備」の3点を解説します。これらを実践することで、監視運用の信頼性と効率性を一段と高めましょう。
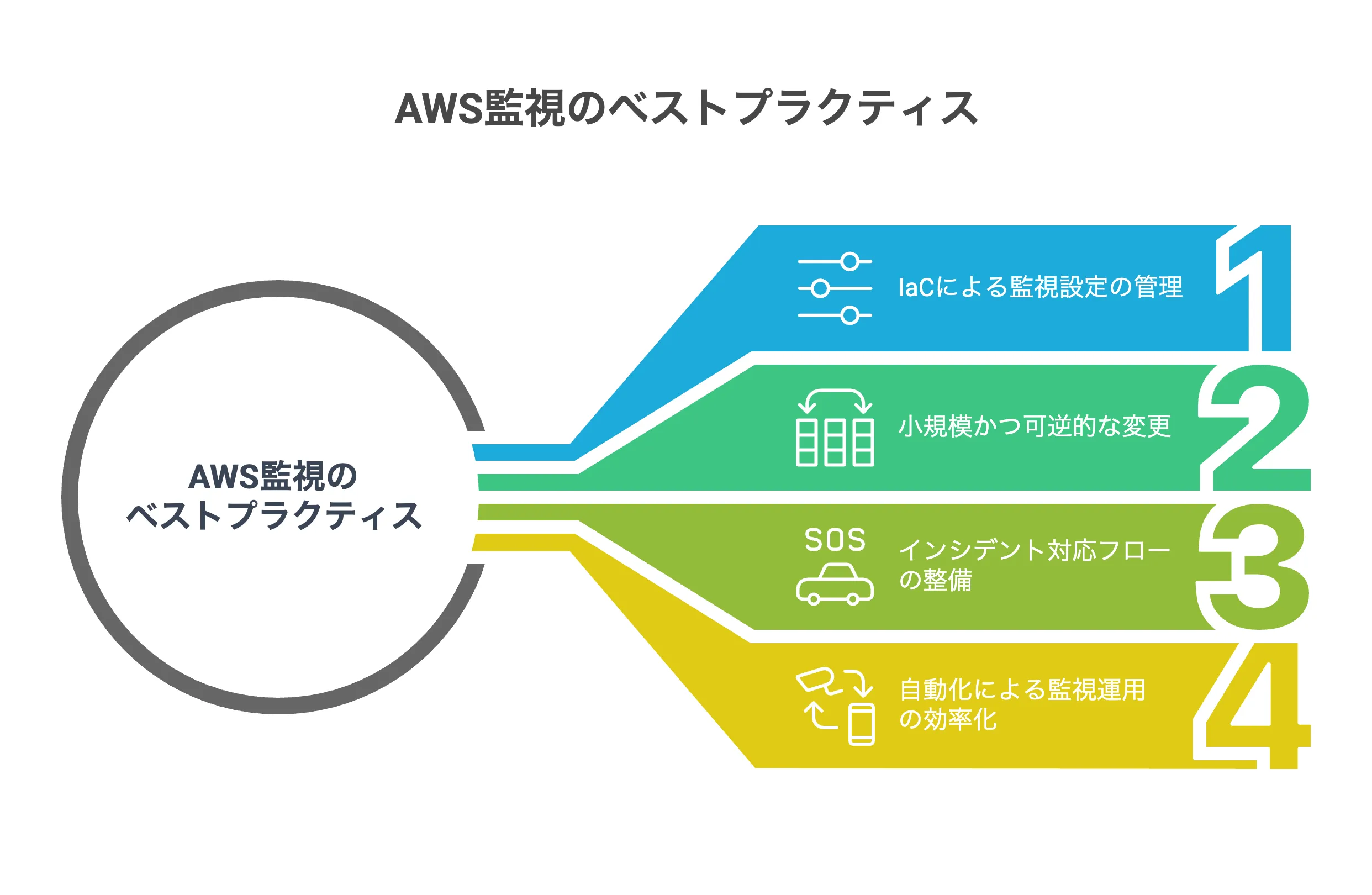
Infrastructure as Code(IaC)で監視設定を管理
クラウド運用において近年重要視されているのがInfrastructure as Code(IaC)の考え方です。監視の設定についても例外ではなく、可能な限りコードで管理・自動化するのが望ましい運用方法となっています※3。
※3 参考:The importance of monitoring as code for modern enterprises
具体的には、CloudWatchのアラームやダッシュボードの定義をAWS CloudFormationのテンプレートやTerraformの設定ファイルで記述し、ソースコード管理しておく方法です。こうすることで、設定変更の履歴管理や環境間の再現が容易になり、ヒューマンエラーの削減にもつながります。
AWSではマネージドな監視設定も多いですが、IaCを用いて他のインフラ構成と一元管理することで監視の構成を他のコードと同様にバージョン管理・自動デプロイできます。例えばTerraformを使えば複数のCloudWatchアラーム設定を一括でデプロイ・更新でき、設定漏れや不整合を防止できます。
また、AnsibleやAWS CDKを活用してログ収集エージェントの導入を自動化するケースもあります。これらIaCツール(Ansible, SaltStack, CloudFormation, Terraform, AWS CDK など)はいずれも有用で、監視やオブザーバビリティの構成管理にも積極的に取り入れるべき※4とされています。
※4 参考:ベストプラクティスの概要
小規模かつ可逆的な変更を頻繁に実施
システム運用全般の原則ですが、変更作業は小さく分割し頻度高く行い、かつ万一の際にロールバック(元に戻す)が容易な状態を保つことが重要です。監視運用においても、新しい監視項目の追加や閾値の調整、ダッシュボードの改修などを行う際は、一度に大規模な変更を入れず少しずつ適用して様子を見る方が安全です。
小規模で可逆的な変更を頻繁に行えば、一度の変更範囲と影響が限定され、問題発生時の原因特定やトラブルシューティングが容易になります※5。例えば監視アラートの閾値を調整する場合、一気にすべての閾値を変えるのではなく、重要度の低いものから段階的に変更して適切さを検証するといったイメージです。また、変更管理システムや構成管理ツールと組み合わせて、誰がどの変更を行ったか履歴を残し、万一不具合が出たらすぐ以前の設定に戻せる体制も整えておきます。
※5 参考:OPS05-BP09 小規模かつ可逆的な変更を頻繁に行う
インシデント対応フローの整備と標準化
どんなに監視体制を強化しても、システム障害やインシデントが完全にゼロになることは考えづらいです。重要なのは問題発生時の対応フローをあらかじめ整備し標準化しておくことです。まず、障害のレベル分類(重大度)を定義し、それぞれのレベルに応じた対応手順や連絡体制を決めておきます。
「深夜でも即時に対処すべきレベル」「営業時間内に対処すればよいレベル」といった具合にランク分けし、誰に何を連絡するか、一次対応者は誰か、を明確にしておきます。また監視項目ごと、サービスごとに発生しうるインシデントの種類と対処手順(障害対応手順書)を用意し、チーム内で共有しておくと対応の属人化を防げます。
例えば「EC2インスタンスでメモリエラー頻発」のアラートが出た場合の手順書には、ログのどこを確認し、どのパラメータを調整するか、といった具体策を記しておきます。インシデント発生時には検知から復旧・事後分析まで一連の流れがありますが、事前に決めたフローに沿って動けるようになると、対応漏れや判断迷いを減らせます。
そして、定期的に模擬的な障害対応訓練を実施し、フローの不備を洗い出して改善することも有効でしょう。インシデント対応を標準化・平準化することで、障害発生時の混乱を最小限に抑え、サービス影響を素早く食い止めることができます。
自動化による監視運用の効率化
監視運用のさらなる効率化を図るうえで、自動化の活用は欠かせません。AWSには運用自動化を支援する様々なサービスがあり、これらと監視を組み合わせることで、人手に頼らない省力化や対応スピードの向上が実現できます。以下では、特にAWS Systems Managerを使った定期タスクの自動化と、SNSやLambdaを活用したアラート通知について取り上げます。
AWS Systems Manager連携での定期タスク自動化
AWS Systems ManagerはAWS上のインスタンスやリソースを一元管理し、自動化するためのサービス群です。中でも定型的な運用タスクを自動化するのに便利なのがSystems Manager AutomationやState Manager、Maintenance Windowの機能です。
例えば「毎週末に開発環境のEC2を停止し、週明けに起動する」といったスケジュール作業は、Systems ManagerのState Managerまたはメンテナンスウィンドウにスクリプトを登録することで自動実行できます。
他にも定期的なディスク容量のチェック&不要ファイル削除、メモリ開放スクリプトの実行、セキュリティパッチ適用など、人手で行っていた定期メンテナンスタスクを自動化できます。さらに、CloudWatchとの連携も容易で、例えばAmazon EventBridgeでスケジュールルールを作成し、指定時刻にSystems Manager Automationドキュメントを起動するといったことも可能です。
このようにAWS Systems Managerの各種機能を活用することで、監視で検知した内容への対処や定期保守作業を自動化し、担当者の手間を大幅に削減することが可能です。
Amazon SNS/Lambdaを使ったアラート通知
前述したように、CloudWatchアラームはAmazon SNS経由で様々なチャネルに通知を飛ばすことができます。基本的なメール通知やSMS通知に加えて、SNSトピックを介してAWS Lambda関数を起動することも可能です。
これにより、アラート発生時に単に通知するだけでなく、カスタマイズした自動処理を実行する高度なワークフローが実現できます。たとえば、Lambda関数内でSlackやTeamsといったチャットツールのWebhookを呼び出せば、運用担当のチャネルにリアルタイムでアラート内容を投稿できます。
さらに、Lambda関数内で問題発生個所の詳細な調査を自動で行わせ、その結果を含めて通知するということも考えられます。例えば「EC2のCPU異常上昇」というアラート時に、当該インスタンスのCPUトッププロセス一覧をSystems ManagerのRun Command経由で取得し、それを添えてSlack通知する、といった具合です。これにより担当者は通知を受けた時点で初動に必要な情報を得られ、対応を迅速化できます。
よくあるトラブルと対策
最後に、AWS監視の運用現場でよく直面するトラブルとその対策について整理します。どんなに監視体制を整えても、運用していく中で課題が出てくるものです。ここでは代表的な3つの問題を取り上げ、それぞれに有効な対処法を解説します。
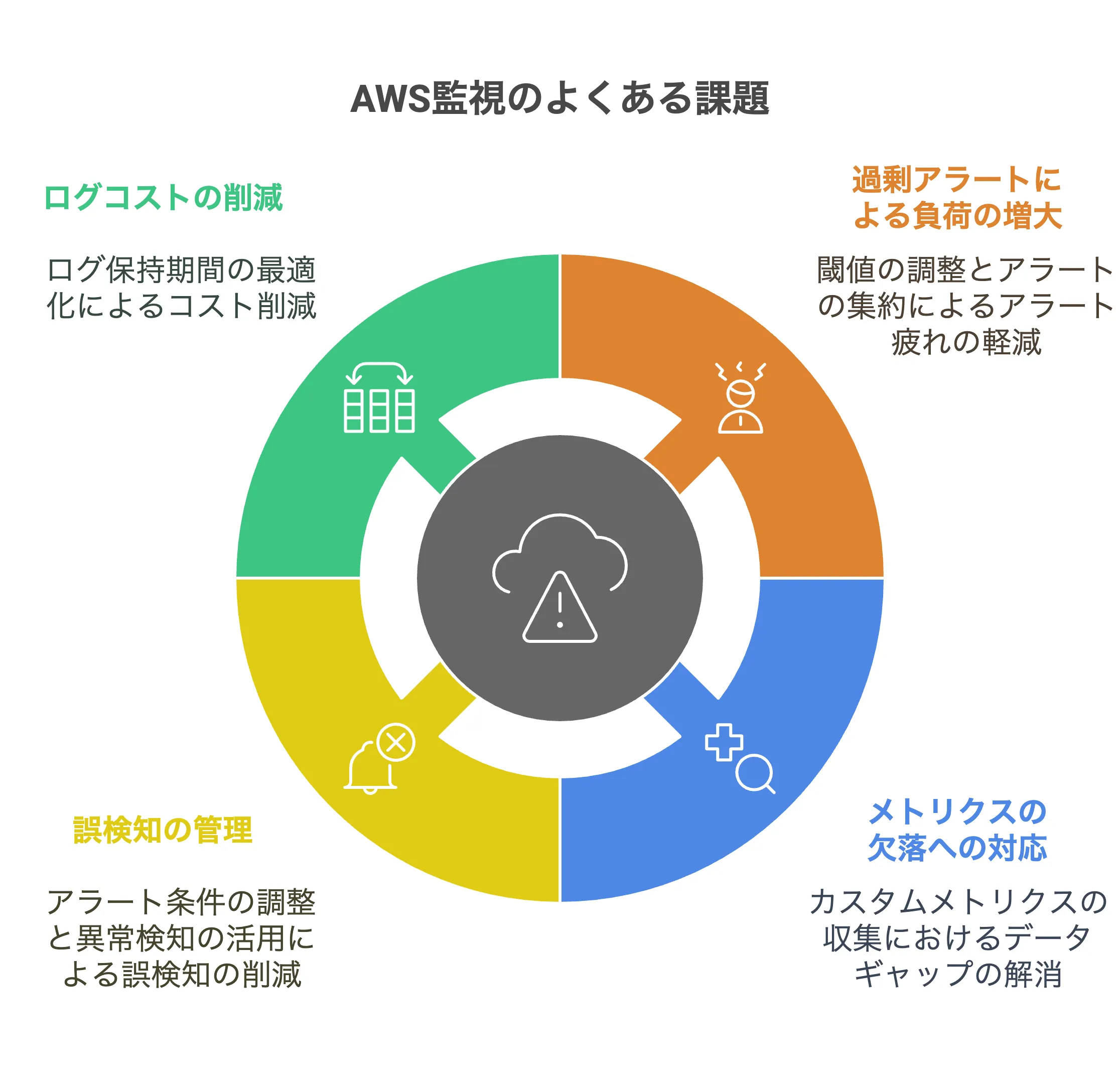
過剰アラートによる人力負荷の増大
監視を強化するあまりアラートが頻発しすぎて担当者の負担が増大するという問題はよくあります。閾値を低めに設定しすぎた結果、軽微な変動でもアラートが飛び、対応に忙殺される「アラート疲れ」に陥るケースです。
対策としてまず行うべきは閾値設定の見直しです。本当に対処が必要なレベルに閾値を上げ、一時的なスパイクや許容範囲内の変動ではアラートが上がらないよう調整します。またCloudWatchアラームの評価期間を延ばしたりデータポイントの連続発生回数を指定したりすることで、「5分以上連続でCPU80%超過」といった条件にし、短期的なピークによる誤検知を防ぐと良いでしょう。
さらにアラートの集約も有効です。単一の根本原因から派生した複数のアラートは、統合して1件のインシデントとして扱う仕組みにします。例えばネットワークの通信断で多数のEC2から一斉に死活監視アラームが発報した場合でも、まとめて「ネットワーク障害」として扱えば通知も一度で済みます。
また、どうしても大量のアラート対応が避けられない場合は、対応の自動化・半自動化を検討します。
前述のSNS+Lambdaの仕組みで、自動エスカレーション(一定時間対応が実行されない場合に別の担当者に通知)や一次対応のスクリプト実行を組み込めば、人手の負担軽減につながります。例えば多数の類似アラートを検知したらチケットシステムに自動集約して記録し、まとめて管理者に通知する、といったワークフローがイメージしやすいかと思います。
メトリクスの欠落や誤検知への対応
監視をしていると稀にモニタリングすべきメトリクスが取れていなかったり、アラームが誤検知を起こしたりする場合があります。前者の「メトリクスの欠落」は例えば「CloudWatch標準では取得されないメモリ使用率を監視対象に含め忘れていた」「エージェント不具合で一部期間のカスタムメトリクスが欠測だった」といったケースです。
これに対しては、必要なメトリクスの洗い出しと取得漏れ防止が大切です。AWS環境ではCloudWatch標準メトリクスだけで見えない指標(例:EC2メモリ利用率やOSレベルの詳細なディスクI/Oなど)があるため、CloudWatchエージェントをインストールしてカスタムメトリクスとして収集することが推奨されます。運用初期に重要なKPIを棚卸しし、欠けている計測項目がないか確認しましょう。
一方「誤検知」は、実際には問題ないのにアラームが作動してしまうケースです。これにはアラーム条件の調整と異常検知ロジックの高度化で対処します。単純な閾値では捉えきれない正常な変動を誤検知してしまう場合、アラームの評価期間やデータポイント数を増やして一瞬のスパイクでは鳴らないようにするのが基本です。
さらにAWS CloudWatchには異常検出という機能があり、機械学習によりメトリクスの平常時パターンを学習して、それから外れた動きをしたときだけアラートを上げることも可能です。これを使えば、たとえば昼夜で使用量が大きく変わるようなシステムでも適応的に異常を検知できます。
ログデータの蓄積によるコスト増大
最後にログデータの蓄積によるコスト増大についてです。CloudWatch Logsにシステムやアプリケーションのログを集約して運用していると、ログデータが蓄積していきディスク使用量や課金コストが増大する懸念があります。
CloudWatch Logs自体はデフォルトでは無制限にログを保持し続けますが、無尽蔵に保管しておくと不要な古いログが溜まり続けることになります。対策として重要なのがログのライフサイクル管理です。
まず、CloudWatch Logsの各ロググループには保持期間を設定することができます。例えば「14日間」や「90日間」と定めておけば、それより古いログは自動的に削除されます。これにより最新の必要なログだけを残し、不要に古いデータで容量を圧迫しないようにできます。
また、長期間保存が必要なログについては、CloudWatch Logsのログデータアーカイブ機能を活用しましょう。CloudWatch Logsでは使用頻度の低いログをアーカイブストレージに移行でき、アーカイブしたログは通常より低コストで保管できます。
さらに別のアプローチとして、一定期間経過後のログをAWS GlueやLambdaで定期バッチ処理し、圧縮してS3に保管するといった方法も一般的です。S3に保存すれば低コストかつライフサイクルルールでさらにGlacier等に自動アーカイブ可能です。
以上、AWS監視について基礎から応用まで詳しく解説しました。監視はシステム運用の「目」となる重要な仕組みです。適切に設計・運用された監視によって、システムの可用性や性能、セキュリティを高いレベルで維持しつつ、無駄なコストを削減することも可能になります。
本記事の内容を踏まえて、自社のAWS環境に最適な監視体制を構築・改善いただけますと幸いです。弊社クロジカでは熟練のエンジニアと独自の監視システムの構築により、お客様の環境を監視して安定稼働を実現することが可能です。AWS環境の監視でお困りごとがございましたらご相談ください。
監修者:クロジカサーバー管理編集部
コーポレートサイト向けクラウドサーバーの構築・運用保守を行うサービス「クロジカサーバー管理」を提供。上場企業や大学、地方自治体など、セキュリティ対策を必要とするコーポレートサイトで250社以上の実績があります。当社の運用実績を踏まえたクラウドサーバー運用のノウハウをお届けします。
コーポレートサイトをクラウドでセキュアに

サーバー管理
クロジカガイドブック
- コーポレートサイト構築・運用の課題を解決
- クロジカサーバー管理の主な機能
- 導入事例
- 導入までの流れ





