
こんにちは。「クロジカサーバー管理」コンサルティングチームの西原です。
Amazon Web Services (AWS) は、世界中の多くの企業や組織が利用するクラウドサービスです。その信頼性は非常に高いものの、完全に障害が発生しないというわけではありません。本記事では、AWSにおける障害の可能性、過去の事例、そして将来起こりうる障害への対策について詳しく解説します。
この記事でわかること
① AWSで起こりうる障害の種類
② 過去にAWSで発生した障害例
③ 将来発生しうる障害への対策
④ 障害発生時のAWSからの補填について
目次
AWSにおける障害発生の可能性
AWSは高度な冗長性と信頼性を備えたインフラストラクチャを提供していますが、様々な要因により障害が発生する可能性があります。例えば、AWSのインフラ側の問題、利用者側の設定やアプリケーションの問題、あるいはネットワークインフラや利用者側の機器の問題など、障害発生の要因は多岐にわたります。
これらの障害は、単一のサービスに影響を与えるものから、複数のサービスやリージョンに影響を与えるものまで、規模も影響範囲も異なります。 AWSを利用する上で、障害発生の可能性を認識し、適切な対策を講じることは非常に重要です。以下では障害の種類や障害が発生しているかどうかの確認方法について触れていきます。
起こりうる障害の種類
AWS側に発生要因がある障害
冷却システムの障害や基盤の障害などで、サーバーが稼働できなくなるといった場合はこちらに該当します。
AWS側に発生要因がある障害
・自然災害:地震、洪水、火災などがAWSのデータセンターに影響を与えるケース
・ハードウェア、ソフトウェア障害:サーバー、ストレージデバイス、ネットワーク機器などの物理的な故障
・人為的なミス:オペレーションミス、ホストOSレベルでのセキュリティ設定の不備など
ユーザー側に発生要因がある障害
下記のような、“クラウド内”の設定不備などのよる障害はユーザー側に発生要因があります。
ユーザー側に発生要因がある障害
・OSやアプリケーションの設定ミス:ゲストOS、ミドルウェア、アプリケーションなどのバグや設定ミス起因の障害
・ネットワーク設定の問題:ネットワーク設定の誤りや不適切な構成が原因で接続障害やデータ転送エラーが発生するケース
・過負荷による問題:ユーザー側で予測外の大量のリクエストが発生し、AWSのリソースが過負荷状態になるケース
・セキュリティ設定の不備:DoS攻撃やDDoS攻撃などのセキュリティ上の脅威による障害
これらの障害は、単独で発生することもあれば、複合的に発生することもあります。例えば、ハードウェア障害がソフトウェア障害を引き起こしたり、ネットワーク障害がアプリケーションの可用性を損なったりすることがあります。そのため、障害の種類を理解し、それぞれの障害に対する適切な対策を講じることが重要です。
障害発生の確認方法
AWSの障害情報を確認する方法はいくつかあります。最も信頼できる情報源は、AWSが提供する公式のサービス「AWS Health Dashboard」です。このダッシュボードでは、全リージョンのサービス単位でのステータスが一覧表示されており、現在の状態や過去の障害履歴を確認することができます。
より詳細な情報を得たい場合は、AWS Personal Health Dashboardを利用しましょう。こちらはAWSアカウントにログインして確認できるダッシュボードで、ユーザー自身が使用しているAWSリソースに影響する障害情報を個別に通知してくれます。また、過去の障害履歴も確認可能です。
その他の障害確認方法
・AWSの公式ではありませんがX(旧Twitter)では「@awsstatusjp」や、「@awsstatusjp_all」から「AWS Health Dashboard」の情報を参照した障害情報がアナウンスされています
・AWS Post-Event Summaryでは、AWS利用者にとって広範かつ重大な影響がある障害について、当該問題の解決後に“問題の影響範囲、問題の原因となった要因、特定されたリスクに対処するために取られた措置”がまとめられたレポートが公開されます
AWSにおける過去の障害事例
AWSは過去にいくつかの大規模な障害を経験しています。これらの障害事例から学ぶことは、将来の障害に備える上で非常に重要です。ここでは、過去の代表的な障害事例を紹介し、その原因と影響、そしてそこから得られる教訓について解説します。
リージョンにおける障害
AWSリージョン全体に影響を与える障害は、甚大な影響を及ぼす可能性があります。過去には、電力供給の問題、ネットワークの障害、ソフトウェアのバグなどが原因で、リージョン全体がダウンした事例がありました。下記ではその一例を見ていきましょう。
東京リージョンでの障害
2019年8月23日、AWSの東京リージョン(ap-northeast-1)で大規模な障害が発生しました。この障害は、1つのデータセンター(アベイラビリティゾーン)における冷却システムの問題に起因していました。
冷却システムの停止により、一部の物理サーバーの温度が許容限度を超え、サーバーの電源が停止し始めました。その結果、同一AZ内のEC2や他のサービスのパフォーマンス劣化が発生し、日本国内では多くのキャッシュレス決済アプリやゲームアプリが影響を受けました。
参照:東京リージョン (AP-NORTHEAST-1) で発生した Amazon EC2 と Amazon EBS の事象概要
その他の東京リージョンでの障害
<概要>
2021年9月2日、東京リージョン(AP-NORTHEAST-1)でAWS Direct Connectの障害が発生し、金融や運輸業界をはじめ多くのサービスに影響を及ぼした。具体的な影響としてユーザーは東京リージョンへのトラフィックで接続問題とパケットロスの被害にあった。
原因はネットワークデバイスのオペレーティングシステム内の潜在的な問題と、フェールオーバー時間改善のために導入された新プロトコルの相互作用によるもの。そして、障害は午前7時30分から午後1時42分まで続いた。結果としてこの事象は、クラウドインフラストラクチャの信頼性と冗長性の重要性を示す障害となりました。
参照:東京リージョン(AP-NORTHEAST-1)で発生したAWS Direct Connectの事象についてのサマリー
米国東部リージョンでの障害
米国東部リージョン(バージニア北部)は、AWSの中でも最も歴史が長く、多くの企業が利用しているリージョンです。過去には、このリージョンでも大規模な障害が発生しています。
例えば、2015年9月20日には、AWSの米国東部リージョン(us-east)で大規模な障害が発生しました。この障害は、Amazon DynamoDBサービスへの新機能追加作業と、同時期に発生したネットワーク障害が重なったことで引き起こされました。
AWSの想定を大幅に上回る利用者が新機能を使用したことと、DynamoDBに利用されている物理サーバーの一部でネットワーク障害が発生したことが相まって、DynamoDBを利用する他のAWSサービス(SQSなど)にも影響が及びました。
参照:Summary of the Amazon DynamoDB Service Disruption and Related Impacts in the US-East Region
その他の米国東部リージョンでの障害
<概要>
2020年にKinesis Data Streamsの障害により、他の多くのAWSサービスにも影響が波及した。本障害は、AWSサービス間の相互依存関係によって障害が拡大するリスクを示したものとして知られている。
参照:Summary of the Amazon Kinesis Event in the Northern Virginia (US-EAST-1) Region
将来起こりうる障害への対策
AWSで将来起こりうる障害に備えるためには、多層的な対策を講じる必要があります。以下では複数の対策について解説いたします。
リスク分散設計(リージョン&AZの冗長化)
AWSにおける最も基本的な障害対策は、複数のリージョンやAZにわたるリソースの分散配置です。例えばリージョン間冗長化は、大規模な自然災害や広域にわたるインフラ障害に対する保険となります。
ただし、リージョン間でのデータ同期や整合性の維持には追加のコストと複雑さが伴うため、ビジネスの重要性と予算のバランスを考慮する必要があります。
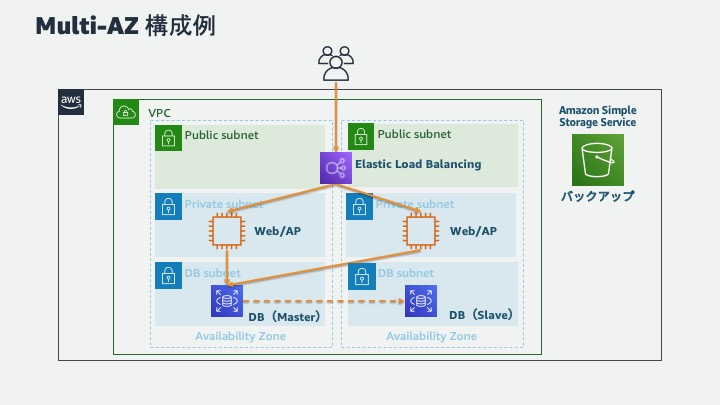
より現実的なアプローチとしては、単一リージョン内の複数AZにリソースを分散させる方法があります。RDSのマルチAZデプロイメントやEC2インスタンスの複数AZへの配置など、AWSが提供する機能を活用することで、比較的コストを抑えてAZレベルの障害に対する耐性を高めることができます。
ここで重要なのは、単なるリソースの分散だけでなく、障害発生時の自動フェイルオーバーの仕組みも併せて実装することです。これにより、障害が発生した際に手動介入なしでサービスを継続できる可能性が高まります。
Auto Recovery
EC2インスタンスのAuto Recoveryは、ハードウェア障害や接続性の問題が発生した際に、インスタンスを自動的に再起動させる機能です。この機能を有効にしておくことで、基盤となるハードウェアに問題が発生した場合でも、新しいハードウェア上で同じインスタンスを自動的に復旧させることができます。
Auto Recoveryを設定する際は、CloudWatchアラームと組み合わせて利用します。ステータスチェック失敗などの特定の条件が満たされた場合に自動復旧が行われるよう設定しておくことで、24時間365日の監視体制がなくても、システムの自動回復が可能になります。
ただし、Auto Recoveryには限界もあります。例えば、AZ全体やリージョン全体の障害には対応できない点や、状態を持つアプリケーションの場合はデータ損失のリスクがある点に注意が必要です。
バックアップ
バックアップは、AWSにおける障害対策の重要な要素です。定期的にデータをバックアップすることで、障害発生時にデータを復旧し、ビジネスの継続性を確保できます。詳細について下記で見ていきましょう。
Amazon Machine Image(AMI)
AMI(Amazon Machine Image)は、EC2インスタンスのバックアップとしても活用できます。定期的にAMIを作成しておくことで、障害発生時に新しいインスタンスを素早く起動することが可能になります。
AMIの作成は自動化することも可能で、AWS Backupや、AWS Lambda、EventBridgeを組み合わせて定期的なAMI作成ジョブを実装できます。重要なのは、作成したAMIが実際に使用可能かどうかを定期的にテストすることです。バックアップがあっても、復元できないということにならないようにチェックしておきましょう。
また、EC2インスタンスだけでなく、RDSのスナップショットやDynamoDBのバックアップなど、各サービスに適したバックアップ手段を利用することで、データ損失のリスクを大幅に低減できます。
その他
上記以外にも、AWSにおける障害対策として、様々な方法があります。
オートスケーリング
Auto Scalingは、トラフィックの増減に応じてEC2インスタンスの数を自動的に調整する機能ですが、障害対策としても有効です。例えば、特定のインスタンスに障害が発生した場合、ヘルスチェックに基づいて自動的に異常なインスタンスを終了し、新しいインスタンスを起動するといったことが可能になります。
Auto Scalingの設定では、最小容量、最大容量、希望する容量を指定できます。最小容量を2以上に設定し、複数のAZにわたってインスタンスを配置するよう設定することで、単一インスタンスの障害に対する耐性を高めることができます。
Elastic Load Balancing( ELB)
ELBは、複数のEC2インスタンス間でトラフィックを分散させるサービスですが、障害対策としても重要な役割を果たします。ELBは定期的にインスタンスのヘルスチェックを行い、異常を検知したインスタンスへのトラフィック転送を自動的に停止します。
特にApplication Load Balancer(ALB)やNetwork Load Balancer(NLB)では、複数のAZにわたるトラフィック分散が可能で、AZレベルの障害が発生した場合でも、正常なAZのインスタンスにトラフィックを転送し続けることができます。
ELBとAuto Scalingを組み合わせることで、障害発生時の影響を最小限に抑えつつ、サービスの継続性を確保することができます。
障害への補償はある?
AWSの障害によってビジネスに損失が生じた場合、補償を受けられるのかという点はユーザーにとって大きな関心事かと思います。AWSではサービスレベルアグリーメント(SLA)を提供しており、各サービスの可用性に対する保証と、SLAを満たさなかった場合のサービスクレジット(料金の一部返金)について規定しています。
例えば、EC2のSLAでは、リージョン内の月間稼働率が99.99%未満の場合、サービスクレジットが付与されます。ただし、その金額は影響を受けた月の請求額の10〜30%程度であり、ビジネス損失全体を補償するものではありません。
また、サービスクレジットを受けるためには、障害発生から30日以内に請求手続きを行う必要があります。そのため、AWSのSLAをよく理解し、障害発生時の対応手順を事前に整備しておくことが重要です。そのため補償額の限界を考えると、SLAに頼るよりも、リスク分散設計やバックアップなどの対策を講じることで障害の影響を最小化する方が、長期的には賢明な選択だと言えるでしょう。

本記事で解説したように、AWSの障害は完全に避けることは難しいですが、適切な対策を講じることで、その影響を最小限に抑えることができます。リスク分散設計、自動復旧機能の活用、定期的なバックアップなど、複数の対策を組み合わせることで、より強固なシステム構築が可能となります。また、障害発生時に迅速に情報を入手し、適切に対応できるよう、日頃からAWSの障害情報の確認方法を把握しておくことも重要です。
監修者:クロジカサーバー管理編集部
コーポレートサイト向けクラウドサーバーの構築・運用保守を行うサービス「クロジカサーバー管理」を提供。上場企業や大学、地方自治体など、セキュリティ対策を必要とするコーポレートサイトで250社以上の実績があります。当社の運用実績を踏まえたクラウドサーバー運用のノウハウをお届けします。
コーポレートサイトをクラウドでセキュアに

クラウドサーバー管理
クロジカガイドブック
- コーポレートサイト構築・運用の課題を解決
- クロジカクラウドサーバー管理の主な機能
- 導入事例
- 導入までの流れ





